
목차
Introduction
일반적으로 사람들이 일을 배울 때 이전의 경험을 살려서 더 쉽게 일을 배울 수 있다. 하지만 RL에는 이러한 prior 정보가 부족해서 처음부터 새롭게 경험을 쌓아햐해서 많은 경험이 필요하다. 이러한 문제를 해결하기 위해서 이 논문에서는 Meta-learning을 활용하고 multi-armed bandits 문제와 tabular MDP문제에 대해서 실험을 진행하였다.
Method
이전 single agent 논문의 object formulation이 한 episode에 대해서 expected return을 최대화는 것이라면 \(RL^2\)는 한 trial에 대해서 expected return을 최대화는 것에 있다. 한 trial은 n개의 episode로 구성되어 있고 아래 그림은 n=2의 trial에 대한 그림이다.
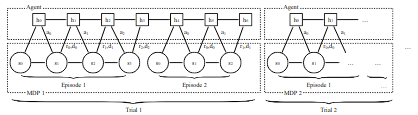 Architecture
Architecture
이 object formulation을 최대화하는 것은 cumulative seduo-regret을 최소화하는 것과 동일하다. 그래서 MDP가 trial에따라 달라지고 다른 전략이 필요하고 agent는 최근의 MDP에 반응하여 동작하게 된다. 그래서 agent는 지난 action, reward, termination flag,을 모두 받아 처리해야하고 이를 전략을 세우는 데 지속적으로 사용하게 된다. 이 과정을 통해 fast RL을 완성하게 된다.
매 time step마다 (s,a,r,d)의 input을 받아 RNN에 넣어준다. 이 논문에서는 vanishing과 exploding gradients의 문제를 해결하기 위해 GRU를 사용했다. 그리고 policy optimization을 위해서 TRPO와 GAE를 이용하였다.
Experiment
Gittins이 만들어낸 전략을 기준으로 RL을 training을 할시 Gittins과 비교할만한 결과를 보여준다고 설명한다. 이 말은 RL을 이용할 시 더 좋은 결과를 보여줄 여지가 남아있다고 설명한다.
 MAB Experiment
MAB Experiment
Tabular 실험 결과에서는 n이 작을 경우 다른 방법 대비 좋은 결과를 보여준다.
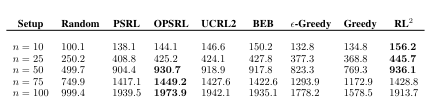
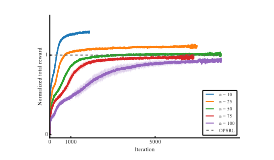 Tabular Experiment
Tabular Experiment