
목차
1. Introduction
2. 환경
3. Case1: sharing sensation
4. Case2: sharing policies or episodes
5. Case3: on joint tasks
6. Concolusion
7. Reference
Introduction
사람들이 일을 하기 위해서는 분업을 하고 있고 곤충들 또한 그렇다. 예를 들어 개미들은 큰 일을 하기 위해서 식량을 옮기는 개미와, 식량을 모으는 개미처럼 각각의 다른 일을 하여 하나의 큰 일을 완료하고자 한다. 현재 RL은 단일 agent에 대해서만 적용하고 있지만 여러 agent를 다룰 수 있다면 더 효율적을 일을 할 수 있다고 생각한다. 여러 agent를 다루기 위해 3가지 방법을 제안한다.
- Agent들 끼리 정보를 공유한다.(sensation, actions, rewards)
- Episode에서 실행 했던 정보를 공유한다.(sensation, actions, rewards)
- Decision policy를 공유한다.
환경
- prey and hunter problem
- Single or multi agent
- 10x10 grid world
- 처음은 random action
- One hunter case: prey와 hunter가 같은 곳에 있을 경우 reward +1 이외 -0.1
- Multi hunter case: Multi hunter가 같은 곳에 있거나 prey 옆에 2개의 hunter가 있을 경우 reward +1 이외 -0.1
- Local 환경만 관측 가능
- depth(볼 수 있는 영역의 크기)가 2 일 경우 (2+1)x(2+1) grid 관측 가능
- state는 prey의 (x,y) 좌표로 표현
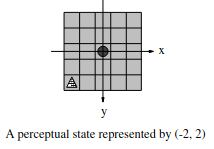
- 그림 1에서와 같이 prey는 hunter 위치를 (0,0)이라고 하였을 때 (-2,2)에 있고 이 값은 hunter의 state가 된다.

그림 1. state 표현 예시
- 그림 1에서와 같이 prey는 hunter 위치를 (0,0)이라고 하였을 때 (-2,2)에 있고 이 값은 hunter의 state가 된다.
- 2개 이상의 prey가 있을 시 랜덤으로 선택, 아무 prey가 없을 시에는 하나의 unique 값을 설정하여 고정값으로 사용
- 매 step 마다 agent(prey or hunter) 상하좌우 action(training 시에는 Boltzman distribution을 사용, test시 max Q value 사용)
- 첫 trial(episode)은 모두 random 위치를 받고 이 후 reward를 받은 agent만 random 위치로 reset
- prey가 죽으면 trial end
Case1: sharing sensation
sensation 공유의 효과를 보기 위한 case이다. 우선 scout agent를 만든다. scout agent는 prey의 위치를 알 수 있으나 직접 잡을 수 없는 agent이다. 실험 방식은 매 step마다 scout의 action과 sensation을 hunter에게 알려준다. hunter는 그렇다면 scout의 action으로 scout의 위치를 알 수 있고 이 위치와 sensation을 통하여 prey의 위치를 알 수 있다.(즉 sensation이 공유되어 prey 위치 정보를 더 잘알 수 있다.)
- ex) scout의 prey sensation 정보가 (-2,2)이고 hunter의 scout 위치 정보가 (2,5)라면 prey는 hunter로부터 (0,7)만큼의 거리가 있다는 것을 알 수 있다.
state의 입력을 고정(x,y 형태를 유지)하여 사용하기 위해서 hunter가 prey정보를 얻을 수 없을 경우 prey의 정보를 사용하는 것으로 설정하였다. scouting agent를 이용하면 search space가 \(26(=5^2+1)\)에서 \(442(=(2 \times10 +1)^2 +1)\)로 perceptual state(지각할 수 있는 상태)가 증가한다.
- 26: \((2 \times 2 + 1)^2\)는 visual depth를 고려한 agent의 visual area이다. 1은 prey가 hunter visual area에 없을 경우가 있다.
- 442: \((2 \times (N_{hunter}* (2*N_{visual\_depth}+1)) + 1)^2\) 2개의 hunter가 서로 정보를 공유한다면 보여줄 수 있는 perceptual state의 갯수는 442개이다.(볼 수 있는 영역의 크기가 아닌 볼 수 있는 state의 갯수로 보는 듯하다)
Case1: 실험 결과
Scouting의 depth를 증가할 때마다 average step이 줄어드는 것을 확인할 수 있다. 그렇다면 두 개의 hunter를 두고 서로에게 scouting agent처럼 행동한다면 어떻게 될까?

Visual depth가 2일 경우 training에서 안좋지만 test에서는 비슷한 결과가 나오는 것을 확인할 수 있고 visual depth를 높일 수록 더 좋은 결과를 보여는 것을 확인할 수 있다. 하지만 그렇게 드라마틱하게 좋은 결과를 보여준 느낌은 아니다.

Case2: sharing policies or episodes
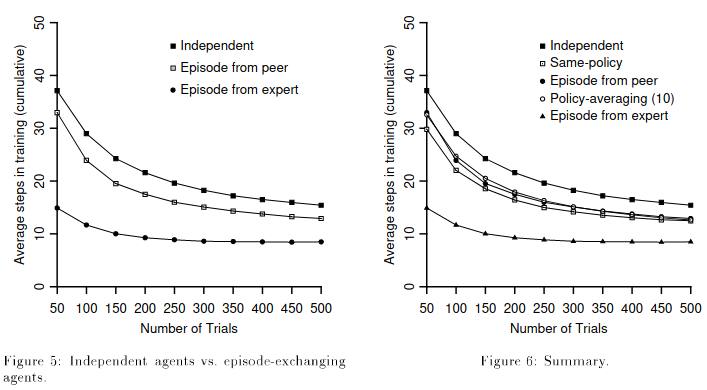
정보를 공유하지 않고 한 가지 일을 한다면 그래도 multi-agent가 유의미할까라는 질문에 대답하기 위한 실험이다. Hunters은 같은 policy를 사용하거나 매 주기마다 개별의 policy를 업데이트할 수 있다. 혹은 episodes가 peer hunter 사이에 교환될 수 있고 peer와 expert 사이에서도 교환될 수 있다.(1,2 번 peer가 서로 다른 경험을 할 것이고 이를 교환하여 자신들의 policy를 업데이트할 수 있다)
Case2: 실험 결과
실험 결과 visual depth와 상관 없이 비슷하게 나왔다. 같은 policy를 사용하는 경우 Independent한 경우보다는 빠르게 안정화되고 좋은 결과를 보여준다. Exploration으로 인해서 agent마다 다른 policy를 가질 수 있다. 그래서 agent의 policy들을 매 n step마다 average를 하여 새로운 policy를 만들도록하는 방법을 실험하였다. Average의 N을 높일 수록 좋지 않을 결과를 보여주고 그래프 상에서는 10일 경우 가장 좋게 나왔고 다른 경우 50일 경우가 가장 좋게 나왔다고한다.
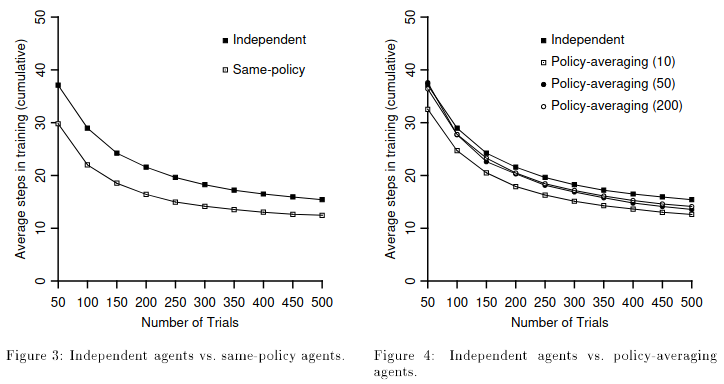
policy를 공유하는 것이 아닌 episode를 공유하는 실험을 해보았다. Peer agent에게 episode를 공유할 경우 policy sharing과 비슷한 결과를 보여주지만 Expert agent에게 episode sharing을 한다면 빠르게 안정되고 더 좋은 결과를 보여준다.
Case3: on joint tasks
두개의 prey와 hunter를 이용한 joint task관련 실험이다. 환경에서 설명했듯이 hunter는 prey를 잡기 위해서 같은 곳에 있거나 prey 양 옆에 있어야한다. Independent한 경우와 차별화를 두기 위해서 passively observing을 이용한다. passively observing은 state를 \((x_{prey}, y_{prey})\)에서 \((x_{prey}, y_{prey}, x_{ptn}, y_{ptn})\)으로 바꿔서 사용한다. \((x_{ptn}, y_{ptn})\)은 partner와 hunter의 상대적 거리이다. 이를 통해 파트너의 상대적거리를 학습에 참고하여 사용한다. 다른 방법으로는 case2처럼 Mutuals-scouting이 있다.
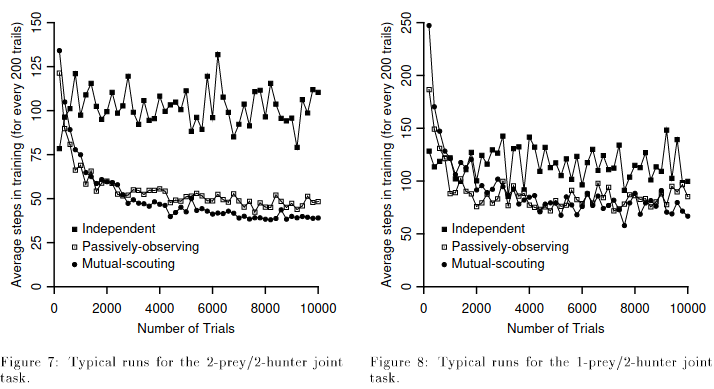
Case3: 실험 결과
Independent의 경우 안정되지 못하고 많이 발산하는 형태로 되어 있다. 하지만 Passively-observing과 Mutual-scouting의 경우 안정적으로 되고 Mutual-scouting의 방법이 더 좋은 결과를 그래프에서 확인할 수 있다. 1-prey/2-hunter 일 경우 Independent의 경우 여전히 발산하는 형태로 보이며 Passively-observing과 Mutual-scouting은 비슷한 결과를 보여준다.
Concolusion
- state space가 너무 커진다. -> x,y로 표현하면 최대 10,10이라고 판단되는 데 왜 state가 많다고할까?, 그리고 이 부분은 현재 DNN을 적용하여 해결
- 1번과 비슷 state space를 줄이기 위해 general technique 필요
- Learning opportunities are hard to come by for nontrivial cooperative behavior. 즉 만약 prey가 똑똑해서 잘 도망치면 학습을 어떻게 할까?
- Information 전달에 문제가 있거나 힘들다면 어떻게할 것인가?
- 다양한 목적을 학습하기 위해서 아직 더 기술이 필요하다.