
목차
- Introduction
- Hierachy of Two Policies
- Parameterized Rewards
- Off-Policy Corrections for Higher-Level Training
- Experiment
- Reference
Introduction
이 논문의 해결하고자 하는 문제는 세 가지 질문으로 압축할 수 있다.
- How should one train the lower-level policy to induce semantically distinct behavior?
- 어떻게 lower-level policy를 학습하게 할 것인가?
- How should the high-level policy actions be defined?
- high level policy action을 어떻게 정의할 것인가?
- How should the multiple policies be trained without incurring an inordinate amount of experience collection?
- Experience efficient를 어떻게 할 것인가?
이전에 이런 질문에 답하기 위한 연구들이 진행되었지만 많은 연구들이 generality가 부족하다고 얘기한다. 이 논문에서는 high level policy를 이용하여 lower level policy를 학습시키고 off-policy를 이용하여 experience efficiency를 높였다. FUN과 비슷하게 high, low level policy 두가지 policy를 사용한다.
Hierachy of Two Policies
lower-level policy \(\mu^{lo}\)와 higher-level policy \(\mu^{hi}\) 두가지 구조를 이용한다. Higher level policy는 lower level policy의 골을 설정하는 목적을 가지고 있다. Higher level policy는 state를 관측하고 매 t mod c가 0이되는 순간 high-level action(goal) \(g_t\)을 \(\mu^{hi}\) 혹은 fixed goal transition function h를 이용하여 생성한다. lower-level policy는 \(s_t\)와 \(g_t\)를 관측하여 low-level action인 \(a_t\)를 생성한다. Higher-level controller는 lower-level에게 intrinsic reward \(r_t = r(s_t, g_t, a_t, s_{t+1})\)를 준다.
HIRO의 구조는 아래와 같다.
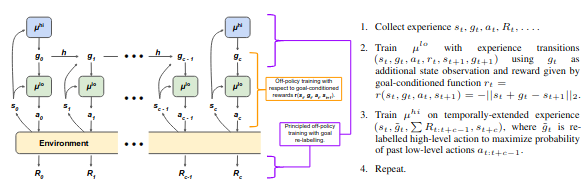 Architecture
Architecture
Parameterized Rewards
Higher-level policy는 goal \(g_t\)를 생성하고 이것은 lower-level agent가 \(s_{t+c}\)가 goal에 가까워지도록 학습하게 만든다. 이때 transition function h는 아래와 같이 정의된다.
\[h(s_t,g_t,s_{t+1}) = s_t + g_t - s_{t+1}\]그리고 intrinsic reward는 아래와 같이 정의된다.
\[r(s_t,g_t,a_t,s_{t+1}) = - \vert \vert s_t + g_t - s_{t+1} \vert \vert _2\]Off-Policy Corrections for Higher-Level Training
같은 입력에 대해 다른 low-level policy를 생성하지 않도록 \(g_t\)는 \(\tilde{g_t}\)로 re-label이 된다. Goal state를 조정하기 위해 off-policy correction이 필요하다. 그래서 이 논문에서는 \(\mu^{lo}\)를 최대화되는 high-level action \(\tilde{g_t}\)를 이용하여 high-level transition을 relabeling한다.
\[\underset{g_t}{\text{argminx}} \underset{i=t}{\overset{t+c-1}{\sum}} \vert \vert a_i - \mu^{lo}(s_i, \tilde{g_i}) \vert \vert ^2_2\]Experiment
Ant gather, max, push, fall 4가지 case에 대해서 실험을 진행했고 실험 조건은 HIRO, with pre-training, No HRL, with lower-level re-labelling, no off-policy correction이다. 한가지 case를 제외하고 HIRO가 가장 좋은 성능을 보여주었다.
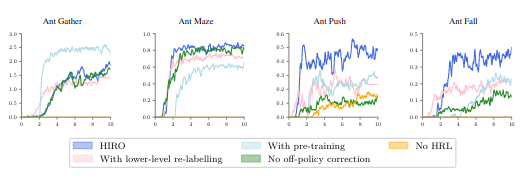 Experiment
Experiment