
목차
Introduction
Sparse reward에 대한 문제를 해결하기 위해 Hierarchical Reinforcement Learning 방법이 연구되고 있다. 이전에 적은 STRAW논문이 하나의 예시 논문이고 이 Feudal networks 논문 또한 같은 문제를 해결하기 위한 논문이다. 이 논문은 Feudal, 계층적 시스템을 이용한 논문이다. 이전 1993에 Feudal RL를 응용한 논문이다. 계층적으로 분석하여 그 중에서 관심있는 부분을 이용하여 학습하도록 한다. 가장 위쪽에 Manager를 두어 worker들을 관리하고 worker들은 manager로부터 명령을 받아 goal에 도달하도록 low-level action을 취하게된다. Manager들은 manager 자기 스스로 학습을 하게 되고 worker들은 worker와 manager를 이용하여 학습하게된다.
FeUdal Networks
FeUdal Networks(Fun)은 2개의 모듈인 worker와 manager로 이루어진 neural network이다. Manager는 latent state representation \(s_t\)와 goal vector \(g_t\)를 출력으로 만들어낸다. Worker는 state와 external observation, Manager의 goal의 입력을 받아 action을 생성해낸다. FuN의 구조는 다음과 같다.
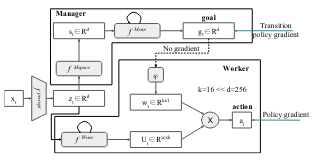
Latent state representation \(s_t\)를 생성하기 위해 CNN와 FC를 사용한다. CNN을 통해 \(z_t\)가 생성되어 이 부분은 Manager와 Worker를 공유하여 사용한다. 만들어진 \(s_t\)를 Dilated LSTM에 입력으로 사용하여 Goal을 생성한다. Dilated LSTm을 사용하는 이유는 Feudal 구조를 생각해서 사용한 것 같다. 이렇게 만든 goal의 차원을 축소한다. 그리고 \(z_t\)와 LSTM을 이용하여 Action space \(U_t\)를 만든다. \(U_t\)와goal의 축소된 데이터 \(w_t\)를 곱하여 최종 action을 만든다.
Learning
Manager를 update하는 방식은 아래와 같다.
\[\nabla g_t = A^M_t \nabla_\theta \text{d}_{\text{cos}} (s_{t+c} - s_t, g_t(\theta))\]where \(A^M_t = R_t - V^M_t(x_t, \theta)\), \(\text{d}_{\text{cos}}(\alpha, \beta) = \alpha^T \beta / (\vert \alpha \vert \vert \beta \vert)\)
Manager는 policy gradient 방식을 이용하여 학습된다. Neural network로 구성되어 있어 fully differentiable하다. Manager는 이롭게되는 transition의 방향을 학습하고 그 결과인 goal의 방향성을 따라 오도록 Worker에 Intrinsic reward를 준다. Manager의 학습 공식에서 \(V^M_t(x_t, \theta)\)는 internal critic이고 \(\text{d}_{\text{cos}}\)는 cosine similarity이다.
Worker의 학습 공식은 아래와 같다.
\[\nabla \pi_t = A^d_t \nabla_\theta \text{log} \pi (a_t \vert x_t ; \theta)\]where \(A^D_t = (R_T + \alpha R^I_t - V^D_t(x_t ; \theta))\), \(R^I_t\) is Intrinsic reward
Worker는 환경 보상뿐만 아리아 manager로부터 만들어진 방향을 잘 학습하기 위해 intrinsic reward를 포함하여 advantage function을 학습하게 된다.
Experiment
Montezuma환경에서 적절히 학습이 되는 것을 확인할 수 있다. 각 time step마다 goal이 잘 생성되는 지 확인한 실험 결과를 포함하고 있다.
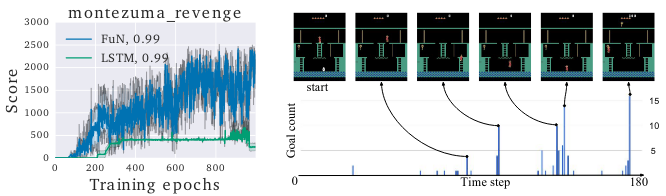 Experiment 1
Experiment 1
실험 비교를 LSTM과 비교하고 있어서 아쉽다. HRL을 타겟으로한 다른 논문과 비교한 부분이 있었으면 좋겠었지만 이 부분은 다른 HRL에서 확인해야할 것 같다.