
목차
- Introduction
- How the vector inputs and outputs of a capsule are computed
- Margin loss for digit existence
- CapsNet architecture
- Comments
- Reference
Introduction
이 논문은 일반적인 CNN의 문제점을 해결하기 위해 새로운 네트워크 구조인 Capsule Network를 제안한다. CNN은 simple feature부터 complex feature까지 점차적으로 바뀐다. 그리고 convolution연산을 하기 때문에(weighted sum) 각 feature간의 위치 관계를 고려하지 않는다. CNN에서는 max pooling을 통하여 해결하고자 하였지만 여전히 feature간의 위치 관계를 고려하지 않는다.
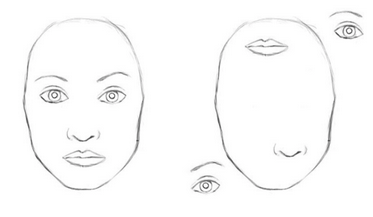 Face Detect
Face Detect
위 그림에서 왼쪽 그림은 얼굴이라고 할 수 있지만 오른쪽 그림은 얼굴이라고 할 수 없다. 하지만 DNN에서는 양쪽 그림 모두 얼굴이라고 칭하는 데 이는 feature간의 위치 관계를 고려하지 않았기 때문이라고 할 수 있다. 저자는 CNN이 사람의 사물을 인지하는 것과 다르게 인지를 한다고 하며 CNN을 사람의 인지하는 방식을 따라 할 수 있도록 CapsNet을 제안한다.
그래서 이 논문에서는 Capsule이라는 새로운 개념을 도입하였다. Capsule은 entity와 entity property로 이루어져있다. 위 그림에서 눈, 코, 입이 entity property라고 한다면 얼굴이 entity라고 할 수 있다. 각 entity property가 어떻게 작동을 할지는 dynamic routing을 이용한다고 한다.
How the vector inputs and outputs of a capsule are computed
CapsNet의 구조는 아래와 같다. Image가 input으로 들어오면 Convolution을 지나고 Convolution의 ouput으로 primary Caps가 나온다. 이때 66192의 3D cube형태로 나오지만 8개의 entity로 나누어 (6632)*8로 구성한다.
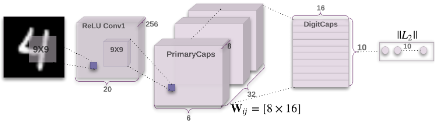 Capsule Network
Capsule Network
 Dynamic Routing
Dynamic Routing
이렇게 나온 primary Caps에 dynamic routing을 실행한다. 이 논문의 non-linear function은 squashing을 사용한다.
\[v_j = \frac{\vert \vert s_j \vert \vert ^2}{1 + \vert \vert s_j \vert \vert ^2} \frac{s_j}{\vert \vert s_j \vert \vert}\]non-linear function squashing의 input을 만들기 위해서 u에 c를 weighted sum을 한다.
\[s_j = \sum_i c_{ij} \hat{u}_{j \vert i}\]where \(\hat{u}_{j \vert i} = W_{ij} u_i\)
u는 primary capsule을 의미하고 W는 weight를 의미한다. 그림에서 8*16으로 되어 있지만 실제로 사용할 때는 4 Dimension이다.
\[c_{ij} = \frac{\text{exp}(b_{ij})}{\sum_k \text{exp}(b_{ik})}\]C는 b의 softmax 값으로 사용된다. b는 0으로 시작되는 초기값이고 아래 식을 이용하여 update 된다.
\[b_{ij} = b_{ij} + \hat{u}_{j \vert i} v_j\]Margin loss for digit existence
capsule의 entity를 위해서 instantiation vector를 이용한다. 이미지에 특정 digit이 있다면 해당 top level capsule에 큰 가중치를 주도록하고 싶다. 그래서 separate margin loss를 사용한다.
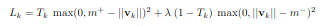 Loss function
Loss function
\(T_k =1\)일 때는 class k 의 digit이 있는 것을 의미하고 이 때 \(m^+ = 0.9\), \(m^-=0.1\)를 의미한다. \(\lambda\)는 0.5로 설정하였다.
CapsNet architecture
Capsnet은 \(v_j\)를 이용해 classification만 하는 것이 아닌 Fully connected layer 3개를 사용하여 reconstruction error loss 또한 이용한다. 이 loss를 추가하는 이유는 digit capsule이 instantiation parameters를 잘 encoding을 하도록 돕기 위해서이다. Margin loss에 영향을 줄이기 위해서 0.0005를 곱하여 scale down하였다. 실험 결과에서는 reconstruction error loss를 이용할 경우 더 좋은 classification 결과를 보여준다고 하였다.
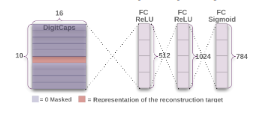 Capsule Network Decorder
Capsule Network Decorder
Comments
Dynamic rounting 부분을 Attention 알고리즘으로 대체하거나 다른 방법을 사용하여 training DNN의 training parameter로 사용될 수 있을 여지가 있어보이고 단순히 MNIST가 아닌 복잡한 데이터 셋의 결과를 알고 싶다는 점이 있었다.